urbanixm is an urban knowledge discovery engine where we process both quantitative and qualitative information to create and curate knowledge about our built environment.
The central part of urbanixm is its knowledge curator. It is responsible of building an urbanism knowledge-base by curating content crawled from the web. The knowledge-base in then used to drive a series of other downstream products and services.
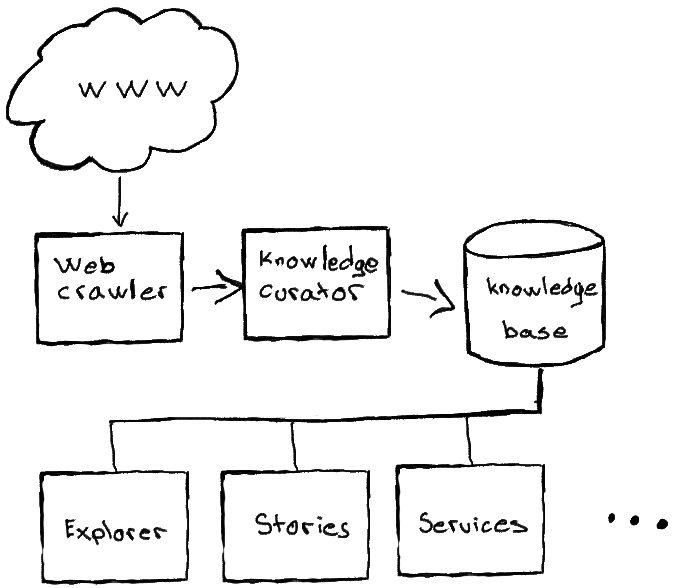
Web crawler
The urbanixm web crawler traverses the world wide web in search of content that is relevant to urbanism. We apply the Apache Nutch crawler on an ever evolving seed of interesting pages we come across.
We collect various types of web-pages, anything from scientific articles and project reports to news articles and press releases.
Knowledge curator
The urbanixm knowledge curator is an artificial intelligence powered pipeline of content annotation tools that processes the pages gathered by our crawler and extracts nuggets of knowledge that we store in our knowledge base.
The curation pipeline is split up into two main phases:
- web-page curation
- quote extraction
Web-page curation
In the web-page curation we process the set of pages collected by our web-crawler. We have developed a machine learned model to recognize if a page is related to urbanism, if it is not, we discard it.
Furthermore, we have built a collection of content classification models to assign other attributes to the relevant pages, such as, the function of the web-page, whether the page content is quotable, which urbanism topics are discussed in the page, and which geographic areas are covered by the text.
At the end of the process we have filtered our original set of pages down to a selection of richly annotated relevant pages.
Quote extraction
Having identified and annotated the relevant web-pages, we pass them through another curation pipeline where we consider shorter text snippets from the pages and judge whether they fit our our mission. I.e. if they are suitable candidates for being quoted in a discussion about urban policy and infrastructure implementation, with a special focus on their social and environmental impact.
The selection of quote candidates is done by applying a set of machine learned models to annotate text snippets with a wealth of attributes, such as,
- what is being discussed, e.g. scene, intervention or impact;
- what is the tone of the discussion, e.g. claims, statistics, goals or predictions;
- what urbanism topics and outcomes are being discussed, e.g. bike lanes, rent control, air quality, gentrification, etc;
- which places are being discussed, e.g. Africa, France or Seattle.
The resulting annotated quotes are stored in our knowledge base.
Knowledge base
The urbanixm Knowledge base is a collection of nuggets of knowledge that can be used in downstream applications through an API.
The API is currently not publicly available.
Explorer
The urbanixm Explorer is a user interface for exploring the contents of the urbanixm knowledge-base.
The Explorer is currently not publicly available.
Stories
The urbanixm Stories are short narratives on the impact of an urban intervention or urban policy. The purpose of the stories is to give a preview of the content of the knowledge base.
Visit our stories page for further information.
Services
We offer services where we use the urbanixm Knowledge base to perform custom studies for our clients, either literature research or other data driven research.
Visit our services page for further information.